This blog was collaboratively written by Kunal and my colleague and friend, Suhail. Together, we explored the topic of RAG to provide a detailed and comprehensive understanding of its key concepts and implications.
At Udhyam, we embarked on an exciting journey to build our own Retrieval-Augmented Generation (RAG) model to enhance our WhatsApp-based chatbot. This blog outlines our experience, the decisions we made, and the challenges we faced. Our goal was to create a system that could provide contextual and accurate responses to students and teachers using the program-related information stored in our documents.
What is RAG? 🤔
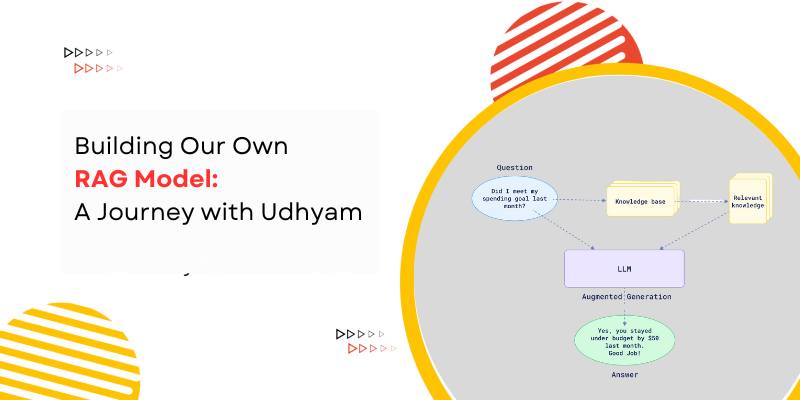
Retrieval-Augmented Generation (RAG) is a method that enhances the capabilities of Large Language Models (LLMs) by integrating them with an information retrieval system. Unlike traditional LLMs, which rely solely on their training data, a RAG model can access external sources of information, such as databases or documents, to generate more accurate and contextually relevant responses.
When a user asks a question, the system retrieves relevant information from external sources (Documents with extra knowledge) and combines it with the query. This augmented input enables the LLM to provide more precise and informed answers, making RAG a powerful tool for improving response quality.
Why did we need our own RAG system ?
We initially relied on Jugalbandi, a RAG-based solution, to provide contextual answers to program-related questions through our WhatsApp chatbot. However, when Jugalbandi stopped supporting the version we were using, we needed to find an alternative.
The lack of in-house AI skills made us hesitant to build our own solution, but after researching RAG, we realized that it was within our reach. The simplicity of the framework and our desire for greater control over the chatbot’s performance encouraged us to take the plunge.
The Development Process: Building the RAG System
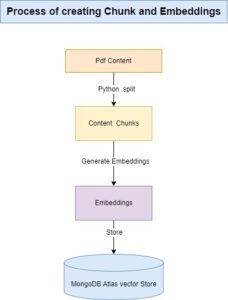
We began by focusing on optimizing the process for cost and efficiency. Our system works by converting the information from program-related PDF files into numerical representations called embeddings, which are stored in MongoDB.
Key Concepts: Chunking vs. Embeddings
Chunking and embeddings are essential concepts in a RAG system, and while they work together, they serve different purposes:
Chunking: This is the process of dividing a document into smaller, manageable parts. In our case, we divided the content based on paragraph separations or by question-answer format. Each chunk represents a coherent piece of information that can be independently searched and retrieved.
Example: If a PDF document has 10 paragraphs, each paragraph is treated as a separate chunk. These chunks are stored individually in MongoDB.
Embeddings: An embedding is a numerical representation of text, capturing its meaning in a vector format that the computer can understand. We use the text-embedding-ada-002 model, known for its efficiency and accuracy, to create embeddings for each chunk of content. These embeddings allow us to perform similarity searches in the vector database.
Example: When a user asks a question, the system converts the query into an embedding and searches for closest embedding in the vector database using a formula, in this case Euclidean formula, retrieving the most relevant content chunks.
Why we chose MongoDB
We selected MongoDB because of its unique combination of flexibility, performance, and native support for advanced use cases like vector search. Our primary need was to efficiently store chunked data alongside their respective embeddings and to quickly search through these embeddings. MongoDB stood out as the best choice for the following reasons:
Schema Flexibility:
- MongoDB is document-based and allows for storing data in a flexible, JSON-like format.
- This is critical for storing embeddings, which may vary in structure and length, along with metadata or additional fields.
High Performance:
- MongoDB is optimized for fast read and write operations, which is essential when dealing with large volumes of embeddings and associated data chunks.
Native Vector Search:
- MongoDB Atlas now supports vector search, which is crucial for our use case. We can store embeddings as vectors and quickly retrieve the most relevant data chunks based on similarity searches using cosine similarity or Euclidean distance.
- The vector search functionality is particularly well-suited for AI-driven applications like semantic search, recommendation engines, and natural language processing tasks.
Implementation Steps:
Content Chunking: We used Python’s .split function to break down the PDF content into chunks, typically based on paragraph separation.
Embedding Generation: The text-embedding-ada-002 model was used to convert these chunks into embeddings, which are then stored in MongoDB using MongoDB Atlas Vector Search with their respective chunks..
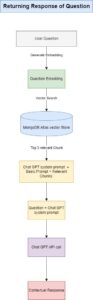
Query Handling: When a user asks a question, the system generates an embedding of the query and uses MongoDB’s vector search to find the top three relevant content chunks.
Answer Generation: The relevant chunks, combined with the user’s question, are sent to ChatGPT to generate an accurate and contextual response.
Each chunk is stored in MongoDB along with its corresponding embedding. When a question embedding is generated, MongoDB’s vector search compares it to the stored embeddings and retrieves the closest matching chunks from the database.
Testing and Comparisons: Exploring Alternatives
During development, we compared our system with other solutions, Including OpenFile search and Jugalbandi. We also explored using the LLaMA model (a free model) to reduce costs. One of our team members had worked on this earlier which helped.
Testing with LLaMA :
LLaMA (Large Language Model Meta AI) is an open-source series of language models developed by Meta (formerly Facebook). It is designed for various natural language processing (NLP) tasks like text generation, summarization, translation, and question-answering. LLaMA is similar to models like OpenAI’s GPT but is trained on publicly available data and optimized to be smaller, faster, and more efficient.
Here are some of the Pros and Cons of using LLaMA model:
Pros:
- Provides accurate answers when asked questions in English based on the provided documents.
- Fast response and Open-source.
- Occasionally responds accurately in Hindi when questions are asked in Hindi.
- A strict prompt structure may yield expected results.
Cons:
- Responses are sometimes delivered in the wrong language. For example, when a question is asked in Hinglish, the answer is received in English.
- Poor understanding of the context, and lower quality responses.
Given the importance of handling multilingual queries effectively, LLaMA was not a viable option for us. GPT-4o outperformed it, especially in understanding and responding accurately to queries in Hindi, English, and Hinglish.
Final Decision: Why We Chose Our RAG System
After thorough testing and comparisons, our RAG model emerged as the best fit for our needs. The combination of Python for speed and MongoDB for efficient embedding storage provided a robust, scalable solution. The entire system was tailored to our unique requirements, ensuring that it met the needs of our users.
Learnings and Reflections
Building our RAG model was a challenging yet rewarding experience. It allowed us to explore various technologies, understand their strengths and limitations, and ultimately create a system that met our specific needs. This journey has opened up new possibilities for Udhyam, and we are excited to see where this technology will take us next.
This journey not only enhanced our chatbot but also empowered our team to delve into AI technologies, fostering a culture of innovation and continuous learning at Udhyam.
Finally, I would like to extend my sincere thanks to Ramesh Krishnamoorthy sir for their valuable insights and contributions to this blog. Their expertise was instrumental in shaping the ideas presented here.

